久しく間が空いてしまいましたが。まあ、コロナ禍で、世間全般が半ば開店休業状態でもあるし。
とはいえ、ぼくはぼくなりに、コロナ蟄居状態をそれなりに楽しんでいる次第で。
その一つが、IPAから信託譲渡を受けた文字情報基盤の成果物に対する、Henry Chenさんからのコメント。文字情報一覧表のUCS符号位置との対応関係がおかしいのではないか、というコメントをいただいた。Henry Chenさんは、IRGで活発に活動している中国の専門家。ぼくは、最近のIRGには参加していないので、多分、直接の面識はないが、名前はよく耳にしている。Chenさんも文字情報基盤に注目してくれているのだ、と思うと悪い気はしない。押っ取り刀で、コメント内容を調べてみた。
問い合わせは二つ。いずれも、MJ文字図形名とUCS符号位置との対応関係に関するもの。
一つが、MJ054422が、現在は、U+2995Cになっているのだが、正しくはU+29946ではないか、というもの。
もう一つが、MJ046645が、現在は、U+26D1Fになってるのだが、正しくはU+26C5Dではないか、というもの。
| MJ文字図形名 | MJグリフイメージ | UCS(現) | UCS(Henry提案) |
| MJ054422 |  |  |  |
| MJ046645 |  |  |  |
調べてみると、どちらも戸籍統一文字に含まれており、大漢和辞典にも収載されている。この際だから、大漢和辞典の該当個所もクロップしておこう。
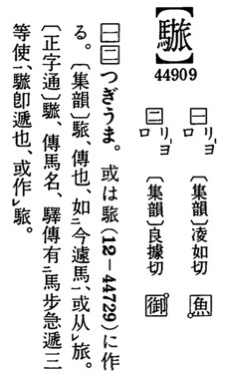

ご覧いただけば、一目瞭然だが、分はChenさんの方にある。
とはいえ、正すは正すにせよ、どうして、そして、いつどこで、このような誤りが紛れ込んだのかが分からないと、いかにも落ち着きが悪い。何よりも、2個見つかったということは、もっとある可能性が高い。これから、文字情報基盤事業成果物が、自治体などの実務システムに使われることがますます増えていくことが想定されるが、実装が増加する前に、正すべきは正しておきたい。
こうして、コロナ蟄居の間の、楽しい暇つぶしの調査が始まった。
調査の大筋は、二つに分かれる。
一つは、MJ文字図形とCJK符号位置の、それぞれどの部分が怪しいかを見極めること。
もう一つは、怪しい部分から、問題になりそうなMJ文字図形名とUCS符号位置の組を洗い出すこと。
MJの文字情報一覧表には、5万字近くの文字が収載されている。また、CJKの側は、今では、9万字ほどもある。
これらを、総当たりで調べるのは、いくら何でも気が遠くなる。何とか絞り込めないだろうか。
最初に頭に浮かんだのが、拡張Bが怪しい、ということだった。
ご存じの方も多いと思うが、UCSの漢字パートは、大きく、統合漢字(Unified Ideographs)と互換漢字(Compatibility Ideographs)に分けられる。さらに、それらに、拡張パートや補遺やらが加わって、今では、9万字余りの漢字に符号位置が与えられている。その中でも、拡張Bは規模も大きく、康煕字典の全ての文字を収載することが一つの大目標になっていたこともあって、一般にURO(Unified Repertoire and Ordering)と呼ばれている初版時からあるパートに次いで重要なパートと言えよう。しかし、今から振り返ると、規模が大きいせいもあって、どうも品質的にはイマイチではないかなあ、という疑念がぬぐいきれない。
それはさておき、康煕字典とともに、大漢和辞典は、規模の点でも信頼性の点でも、中国や台湾も含めた漢字圏内では非常に高く評価されている。余談ではあるが、台湾には大漢和辞典の海賊版が売られており、紀田順一郎さんなどは、「台湾の海賊版の方が紙質が悪い分、軽くて使いやすいぐらいですよ」とおっしゃっていたことを記憶している。
閑話休題。当然ながら、康煕字典は大漢和辞典編纂の折の基本典拠の一つだったわけで、収録字数もほぼ同規模になっている。
そして、日本の行政における人名用漢字使用(特に姓)の拠り所となっている戸籍統一文字は、法令に則ったこともあって、大漢和辞典を初めとする市販の大規模漢字辞典の見出し字を原則的にはすべて含んでいる。
というわけで、拡張Bを含むUCSが発行されたのが2001年で、汎用電子情報交換環境整備プログラムが開始されたのが2002年なので、汎用電子〜が開始された時点で、拡張Bはすでに国際規格として成立していたことになる。
汎用電子〜のプロジェクトメンバーが、戸籍統一文字に対応するUCSの符号位置を調査しようと試みたとき、その対象の多くが拡張Bに含まれていたことは、このような経緯から、ほぼ確実なことだった。ぼくが、「拡張Bが怪しい」と思ったのは、このような背景があったからに他ならない。(ま、急いで付け加えておくと、後から冷静に考えてみると、という条件付きではあるのだけれど。)
この辺りの事情を、汎用電子情報交換環境整備プログラムのころから一貫してこのプロジェクトの係わってこられた、国立国語研究所の高田智和さんに、メールで問い合わせてみた。何度かのやりとりがあったのだけれど、経緯を簡単にまとめると、だいたい以下のようなことだったようだ。
汎用電子情報交換環境整備プログラムから文字情報基盤整備事業に至る一連の活動は、戸籍統一文字と住基ネット文字という成立時期も策定方法も全く異なる二つの独立した文字集合を、UCSという国際的に認知された公的規格をピボットとして関連づける営為だった。
そこで、UCSとともに重要な役割を果たしたのが、大漢和辞典という民間で編纂された世界的にも評価が高かった漢字辞典だった。(※IRGで同文書局版の康煕字典がいわばバイブルとして用いられたこととを考え合わせると何だか興味深いなあ)
汎用電子情報交換環境整備プログラムの始めのころは、JIS X 0221解説のUCS(拡張Aまで)大漢和対応表が、ピボットとして用いられた。
※このJIS X 0221は、2001年に発行されたもので、ははは、ぼくも原案作成委員会の一員に名を連ねている。問題の対応表は、解説付表1というもの。
その後、汎用電子情報交換環境整備プログラムでは、UCS符号位置の範囲を拡張Bにまで拡張して、調査を行った。
文字情報基盤整備事業では、この汎用電子情報交換環境整備プログラム成果(拡張BまでのUCSとのマッピング)を前提として、UCSとのマッピングがないもののUCSへの追加提案がなされた。さらに、UCSで統合されるものについては、IVDへの登録がなされた。
そういうことか。この汎用電子情報交換環境整備プログラムにおける対象文字(戸籍統一文字と住基ネット文字の和集合)とUCS拡張B符号位置との対応関係調査でバグが紛れ込んだのだ。他の部分については、曲がりなりにもISO/IECやJISなどの公的規格に拠り所がある。
急いで付け加えておくが、その後の調査で、さらに20個所弱の疑問点が浮かび上がっているけれど、それでも対象となるペアの0.1%以下なのだ。関係者の間では常識となっているが、UCSそのものにも(特に拡張B)まだバグが残っていて、時々思い出したようにエラーレポートが報告される。ある程度以上の規模の文字集合間の対応関係にバグやバグとは言えないまでの見解の相違が含まれるのは、不可避なことなのだ。
どうも、問題は、現象面としてのバグにあるのではなく、文字情報一覧表に記載されているMJ文字図形名とUCS符号位置との対応関係の一部(というか半数以上)に、UCSやJISなどの公的規格に拠り所を持たないものがある、という点にあったのだ。
経緯を整理したおかげで、俄然視野が拓けた。問題の要は、UCSのJソースなのだ。と言っても、一般の方々には何のことだかチンプンカンプンに違いない。UCSに記載されている典拠情報(ぼくらの中ではCJKソースと言い習わしている。日本提案のものは、Jソース)について、ちょっと説明しておこう。
UCSの規格票をご覧になったことのある方々は、お気づきだと思うけれど。規格票のCJKパートには、例示字形の下に、何やら訳の分からないアルファベットと数字の組合せが記されている。先に挙げた、Henry Chenさんのコメントの例だと。
UCS2003とかGXX-1442.30とかTF-667Dとか。
これらは、関係者の中ではCJKソースといか典拠情報とか呼ばれていて、それぞれの国や地域からの提案の拠り所となる規格を示している。
もちろん、日本から提案した物には、一番最初がJで始まるおまじないが付いている。

へへへ。ぼくの名前の「龍」の例だと、左から4番目のJ0-4E36というのが、日本の原規格で、最初のUROが制定されたころから入っているJIS X -208起源ということが分かる。文字情報基盤整備事業の過程で日本から提案されたものもある。
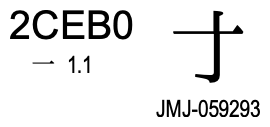
これって、一部の業界人(文字コード屋)の間では有名な文字なんだけれど、これだけで「えだなし」と読む。「木」から枝をはらった文字だから「えだなし」。
こうして見てくると、文字情報一覧表に記載されているUCS符号位置の一定程度(調べてきたら2万字強)は、UCSの側に、MJを含む日本の規格(JIS規格だけではなく、ARIBなどの業界規格も含む)の情報が記載されていることが分かるだろう。
文字情報基盤の文字情報一覧表に記載されたMJ文字図形名とUCS符号位置との対応関係が、UCSの側に拠り所を持っているとは、すなわち、UCS符号表の該当位置に、Jソース(MJ文字図形名やJISだけではなく業界標準も含む)が記載されている、ということに他ならない。今回のChenさんからのコメントに即して考えてみよう。
Chenさんコメントの分は、誰がどう見ても、Chenさんの方にある。これって、明確なバグだから直さなくっちゃ、と思う。
しかし、文字情報一覧表も、MJ明朝も、すでに様々なところで実装されて用いられている。該当する文字がどこかで使われている可能性はゼロではない。とすると、例の後方互換性の問題が出てくる。あるフォントの特定の符号位置の表示字形を恣意的に変更すると、どこでどのような不具合が生じるか、ちょっと予測がつかない、というか、どこまで行っても予測不可能な不具合が生じる可能性が残る。この厄介な問題のおかげで、UCSでは、一度決めた文字名や例示字形は原則的に変更を行わない。やむを得ず変更する場合も、可能な限り既存の情報を残した上で、新しい符号位置や例示字形を追加し、変更情報は規格本文に明記する。
この伝で行くと、文字情報一覧表の情報は、更新履歴を明記した上で変更し、MJ明朝は、既存のUCS符号位置から該当MJ文字図形への対応を残したまま、新たな(正しい)UCS符号位置から該当MJ文字図形への対応を追加することになるだろう。
しかし、というか、それでも、というか。
オープンな環境で使われることが前提となっている文字情報一覧表やMJ明朝フォントの情報を、発足間もない弱小一般社団法人が、そうやすやすと変更してしまって良いものだろうか。
どうやら、当面の結論にたどり着いたようだ。
文字情報技術促進協議会としてなすべきこと。
- MJ文字図形のうち、対応するUCS符号位置にJソースの記載がないものについて、再調査して、さらなるバグの低減を図る
- その上で、しかるべきルートで、UCSへの該当MJ文字図形名の追加を提案する。
ああ、やっとスッキリした。
再調査の具体的なやりかたについては、技術的な話も含めて、いずれ。