Chanさんからのコメント
中国のHenry Chanさんから、また、コメントが来た。日本の外からくるコメントは、ことのほか嬉しい。
しかし、今回のコメントの一つには、いささか、というか、かなり頭を抱えてしまった。
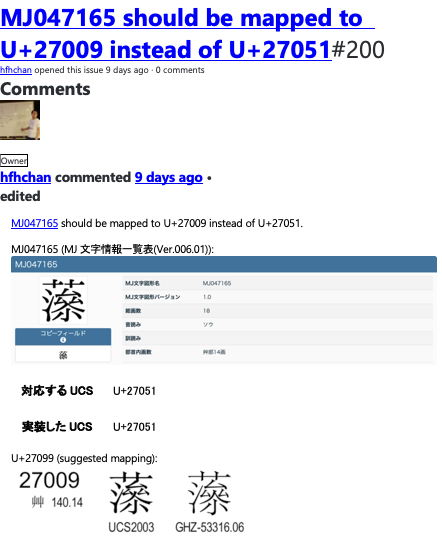
内容的には、先にもらった2件のコメントと同様で、MJ文字図形名とUCSとの対応関係のバグ。
先にもらった2件のコメントを受けて、いろいろ調べまくって、汎用電子情報交換環境整備プログラム時代の大漢和辞典とUCS符号位置との対応テーブルが怪しい、というところまでは当たりを付けて、現在の文字情報基盤資料をベースにした大漢和辞典とUCSとの対応テーブルと、このテーブルとは独立に調査作成された別のテーブル(NTTの川幡太一さんの力作)とを、ぶつけ合わせて、同じ対応関係のものは正しい、と仮定し、何らかの齟齬のあるものに絞って、当協議会のエキスパート会員で、文字情報基盤委員会の委員長をお願いしている国立国語研究所の高田智和さんや、同じくエキスパート会員で京都大学の安岡孝一さんに中心になってもらってレビューをやり、それなりの個数(30組ぐらい?)を、訂正候補として洗い出した矢先だった。
Chanさんの今度のコメントを調べてみたら、何とMJのテーブルと川幡さんのテーブルが共に同じ過ちを犯していることが分かってしまった。ありゃりゃ。
水平拡張計画
以前書いたことだけれど。
[https://moji.or.jp/2021/06/03/mj%e6%96%87%e5%ad%97%e5%9b%b3%e5%bd%a2%e5%90%8d%e3%81%a8ucs%e7%ac%a6%e5%8f%b7%e4%bd%8d%e7%bd%ae%e3%81%a8%e3%81%ae%e5%af%be%e5%bf%9c/]
Chanさんから新たなコメントをもらう前から、当協議会では、UCS策定を担当しているISO/IEC JTC1/SC2のミラーボディである情報処理学会文字情報規格調査会SC2専門委員会(JSC2)とも相談して、MJ文字図形名のうちUCSに日本ソースとしての記載がないものについて、すべてMJ文字図形名を記載する提案(いわゆる水平拡張)を行うべく、準備を始めていた。
文字数が多いとは言え、作業的には、それほど厄介なことではない。しかし、提案にバグが残っているとすると、これはちょっと厄介なことになる。公的標準規格になることで、バグが固定化されてしまう。一旦、公的規格として固定化されたバグは、おいそれとは変更することが出来ない。だからこそ、提案する母体としても、提案を審議する主体としても、慎重の上にも慎重なレビューをすることが求められる。ま、UCSにもまだバグは残っていて、特に、CJK拡張Bなど、いまだに、ポチポチとバグレポートが上がってくる。
今回水平提案を予定しているMJ文字図形は、合計すると3万字以上あるので、ぼく自身の経験を踏まえても、バグを根絶することはおそらく不可のだろう。だからといって、適当にお茶を濁すというわけにも行かない。
そんなわけで、意を決して、提案文字全てのUCSとの対応関係について、提案者として改めて悉皆レビューを行うことにした。
そこで、お願い、というか。
このレビューに、このブログを読んでくださっている方々にも参加していただきたいのだ。
以前著した「ユニコード戦記」のまえがきに、ぼくは以下のようなことを書いている。
符号化文字集合にみならず、情報標準は、一般のユーザーにとっては、通常は意識に上ることすらない所与のものであろう。しかし、すべての情報標準は、その開発にかかわった人々の営為の結果であり、開発の過程には悲喜こもごもさまざまなドラマがある。
ぼく的には、公開レビューによって提案文書のバグを少しでも減らしたいという思いとともに、当協議会がIPAから引き継いだ文字情報基盤の成果物を何らかの形で利用されるみなさまに、主体的な当事者として、ご自分のものとして活用していただきたいなあ、と思っているのだ。パブリックレビューに加わっていただくことにより、そのような「自分のもの感」を持っていただければなによりも嬉しい。
具体的なお願いは、改めてすることになると思うが、このブログの読者諸兄姉の積極的な御協力を懇願する次第。